
This is a blog post about trying to make a figurine of a character from Pantheon. Pantheon a very good TV show. You should go watch it right now. This will be waiting for you when you get back.
Without too much in the way of spoilers, Pantheon has this one robot in it, and it's just about the cutest robot design ever. Look at her.

I need her, but there's just about no merch for this show at all, so I'm gonna have to get my hands dirty and make it myself.
The Tragedy
Because of some disastrous tax optimization by AMC (did you know AMC produces television??), Pantheon was destroyed for a tax write-off despite season 1 being released and season 2 being fully completed. I'm told that Amazon bought the rights to show it at around the same time, somehow ending up with the distribution rights to a (mostly) legally nonexistent TV show. Thankfully, AMC hadn't broadcast it in Australia and New Zealand yet, so Amazon could get around the legal tax destruction thingie and put both seasons on prime video there! From there, the rest is history and you can watch it either through a VPN with Prime Video or through some other less scrupulous means.
Anyway, because of this whole destruction bullshit, this show has not received the attention it deserves, and by extension, the merchandising I so desperately need. If I'm going to get a desktop figurine of Raine, I'm going to need to take things into my own hands.
The Plan
The basic plan is really pretty simple:
- Find every photo of Raine in the entire show, to collect as much reference material as possible.
- Make a 3d model of her
- 3d print her on a resin or SLS printer and paint away
The show is pretty long, and Raine is not quite a main character, so she appears pretty infrequently in a rather long show. I don't really want to page through the entire show manually to find every time she appears, so we need a plan to automate step 1!
I also am ATROCIOUS at art. I can't draw and Blender has a scary number of buttons, so I'd really rather not make the model myself, leaving me with a few options. I can either commission the 3d part from an artist or try to do do the 2d→3d conversion with an AI tool. We'll get to this slightly later.
Thankfully, I'm pretty good at 3d printing, having been in the hobby for years, and am lucky enough to have access to both resin and SLS powder printers, so I'm pretty sure I can make the figurine once I get there.
Part 1 - Reference Materials
There's 16 episodes of this show and each one is 45 minutes long. Even with how good Pantheon is, I really don't feel like scrubbing through 12 hours of show right now, so I need a cheap way to automate this. I think I have a plan in mind.
Robit Detection
If I want to do automatic whats-in-an-image processing, the first things that come to my mind are YOLO, CLIP, or training my own classifier. YOLO is a model that detects what kinds of objects are in images, and CLIP is designed for text/image vector embedding, but neither are quite what we want here. First, I don't think Raine will reliably be tagged as any one thing by YOLO. Her design is a rice cooker with a tablet and legs attached, so while she looks pretty robot-y to you and I, she really isn't the platonic ideal of Robot and I expect this will trip up YOLO. This same thing might cause issues with CLIP - it's a frankly pretty stupid model on it's own and finding a good text embedding at the centroid of all images that contain Raine is not going to be very easy. Finally, I could train my own classifier but that would require getting a lot of samples of Raine to train it on and that's the entire task I'm trying to automate here, so a bit of a non-starter.
Another option is to throw an overkill cloud language/vision model at this task! They've been getting way cheaper recently, with the likes of GPT 4o-mini and the cheap anthropic models, so I think this should be workable with a bit of pre-processing. Some quick back of the napkin math says 4o-mini's vision pricing will let me process about 2000 images for $1, which sounds sweet. Some very quick testing seems to show that it's smart enough to handle this task, so let's get started!
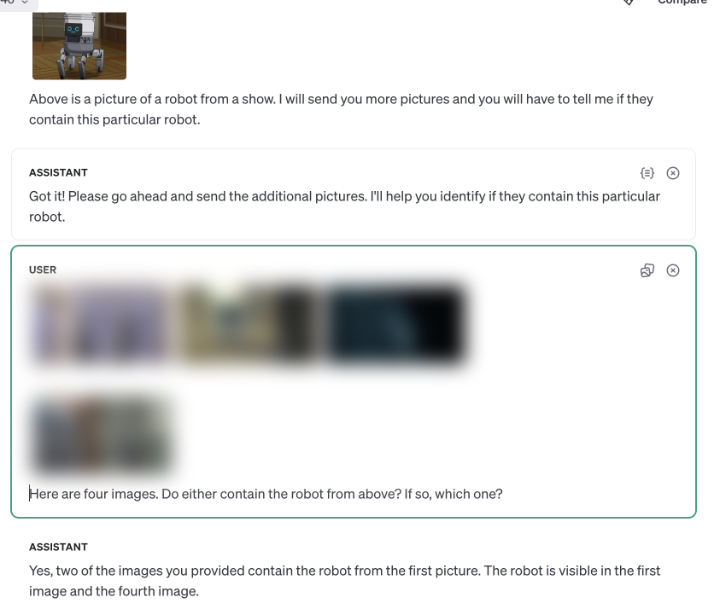
Image Deduplication
The show runs at 24fps, so we have (roughly) 1,036,800 frames total. I'd really rather not spend $500 on OpenAI credits for this, so we need to do some simple preprocessing where we can be confident we won't lose useful reference images.
The MP4 Standard
MP4 is a really cool compression standard that I don't fully understand and really don't have the time to get into here. At a high level, it's based around the idea of keyframes and transformations, where it occasionally (when the video changes dramatically or just every so often) saves a full image of what's on screen and fills in the in-between frames using transformations and partial images. This works great for video, since most frames are very similar to their neighbors and you usually can't tell small issues at a high framerate.
We can use this to our advantage - mp4 videos have what's basically an over-sensitive "shot detector" baked right in! With one ffmpeg command, we can extract every keyframe from a video file.
ffmpeg -skip_frame nokey -i {{source}} -vsync vfr {{dest}}/keyframe%04d.pngffmpeg command that pulls keyframes out of a videoGreat! Pretty easy, runs super fast because it's basically just copying from the file, and cuts it down by about 100x!
Under manual review though, this didn't quite work as well as I wanted. Here's the first 9 keyframes:

You can (sort of) see that across these 9 frames, there's only 4 scenes, each of which has 3 repeats that are almost identical. This isn't really great since every frame is gonna cost me a small fraction of a cent to know if it has our cute robot in it! We have to find a way to solve this nearly-but-not-quite identical image problem...
Thank God For Early 2000s Computer Vision Research
So it turns out, there's already a tool that pretty much neatly solves this problem for us! We can use the Structural Similarity Index Measure (SSIM), which tries to approximate how similar two images look to a human eye.
I'm not entirely clear on the details beyond reading the wikipedia, but in summary it calculates the amount of similarity by looking at the comparison, structure, and luminance of some sections of each image, multiplying the three results, and then averaging this calculation across many, many patches of some known size in the image. It outputs a value between -1 and 1, with 1 being very similar, and it's built into skimage, so we can load it right up and use it in our python!
Here's a super basic loop that runs this process:
from skimage.metrics import structural_similarity as ssim
import cv2
# A list of filenames we want to process. We'll read these from disk.
keyframe_filenames = [
"keyframe0001.png",
"keyframe0002.png",
...
]
# How similar two images need to be to be the "same."
# I found 0.6 to work well after about 3 random tests.
similarity_threshold = 0.60
previous_image = None
for frame_name in keyframe_filenames:
# Load the current image and convert a copy to grayscale
current_image_color = cv2.imread(frame_name, cv2.IMREAD_COLOR)
# We need the greyscale version to run SSIM
current_image_gray = cv2.cvtColor(current_image_color, cv2.COLOR_BGR2GRAY)
if previous_image is not None:
# Calculate SSIM between the previous and current image
similarity_index, _ = ssim(previous_image, current_image_gray, full=True)
if similarity_index > similarity_threshold:
continue # Skip saving this frame if it's too similar to the previous frame
# Save the frame if it's different enough
cv2.imwrite(frame_name, current_image_color)
# Update the previous image
previous_image = current_image_grayWe load each file in, compare it's SSIM to the previous image, and then write it out if it's similar enough! We get a total of 3884 images, or another ~2.5x reduction in images to process from our previous step. If we take a quick look at the frames too, we can see we get a lot more variation, and do a much better job catching unique shots!

With this part done, we can move onto the actual detection!
GPT4o Vision - Cheaper than you can possibly imagine
Great! Now we have about 4,000 unique shots and need to tell which ones have Raine in them. I could look at them all I guess, but I really don't think that's a great use of my time. Instead, I can make a machine do this task for me! If you've done a lot with language models this section might be pretty basic, but if not hopefully there's something useful here for you!
GPT4o (and it's faster, cheaper younger sister GPT4o-mini) are the new multimodal language vision models from OpenAI, and they work really really well. I started this section by doing some quick testing on the OpenAI playground, coming up with a prompt that worked pretty well. You saw this at the top: I show it an image of Raine for reference then show it a series of frames and it's able to easily tell me which frames contain our little metal friend.
I also tested and added a few other optimizations. When feeding multiple images into these models simultaneously, it's best to bake a sequence number into the image itself to ensure that the model never gets confused about which image is which. This was more annoying than it should have been to do using PIL's ImageDraw class, but with some fiddling I got bright red sequence numbers showing in the top left corner of each image.

I also setup tool use, aka function calling, for the outputs. Instead of a text output like we got in the demo, this gives us responses matching the parameters of some function we define! This was meant to allow the model to pause and gather external data, run some code, or make a calculation. However, it also works great as a way to get a property structured JSON response, every time! We really want that use, so let's set it up.
Essentially, we're defining a dummy function that looks like this, and telling our model to "call" it for every image it's passed:
# This is our hypothetical "function" that we tell ChatGPT exists
def report_image_contents( # Item 1 - Function Name
image_id: str, # Item 2 - Parameter Name
contains_robot: bool # Item 3 - Parameter Name
) -> None:
""" # Item 4 - Longform Func Description
Report if an image contains a robot or not.
Call this whenever you need to tell the user
if an image contains a robot or not.
# Item 5 and 6 - Longform parameter description
image_id: str The ID of the image to report on.
contains_robot: bool Whether the image contains a robot or not.
"""
passThe model doesn't actually parse python signatures and docstrings, so instead we create this JSON blob with fundamentally the same information. Watch for matching fields from the function definition above!
{
"type": "function",
"function": {
"name": "report_image_contents", # Item 1
"description": "Report if an image contains a robot or not. Call this whenever you need to tell the user if an image contains a robot or not.", # Item 4
"parameters": {
"type": "object",
"properties": {
"image_id": { # Item 2
"type": "string",
"description": "The ID of the image to report on." # Item 5
},
"contains_robot": { # Item 3
"type": "boolean",
"description": "Whether the image contains a robot or not." # item 6
}
},
"required": [
"image_id",
"contains_robot"
],
"additionalProperties": false
},
"strict": false
}
}This is used by OpenAI somehow in the model's system prompt, presumably in some way they explicitly trained the model to support, and the model will 1) decide if it needs to call the function and 2) provide a properly formatted response if it does! We make sure it decides to by.. literally just telling it to, and then we're off to the races.
To tell it what to do, we use a prompt - basically a snippet of a conversation we want it to complete! The code follows below, but the conversation basically looks like this:
- [user]: <picture of robot> "Above is a picture of a robot. Tell me if the following images are of the same robot. Only use the function to report your answer."
- [ChatGPT]: Understood!
- [user]: <many pictures that may be of robots> "Here are <some number> images. Use the function
report_image_contentsfor each image to tell me if they contain the robot."
When we submit this prompt to OpenAI, they have ChatGPT complete the next turn of the conversation. In our case, this means it calls the function report_image_contents for each image as we asked it to! We can then treat this as JSON, decode it, and use it to pull aside all images that contain Raine!
For completeness's sake, here's how that prompt looks in code:
image_elements = [
{
"type": "image_url",
"image_url": {"url": "<a url>", "detail": "low"},
}
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_to_data_url("./testing/reference.jpeg"),
"detail": "low",
},
},
{
"type": "text",
"text": "Above is a picture of a robot. Tell me if the following images are of the same robot. Only use the function to report your answer.",
},
],
},
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "Understood!",
}
],
},
{
"role": "user",
"content": [
*image_elements,
{
"type": "text",
"text": f"Here are {len(image_paths)} images. Use the function report_image_contents for each image to tell me if they contain the robot.",
},
],
},
],
# ... model settings (removed for brevity)
tools=[json.load(open("function.json"))], # That json from earlier
)
# Access the actual tool calls!
print(response.choices[0].message.tool_calls)On my test set of 10 positive and 10 negative cases I manually dug up, this worked 100%, so that's great! I threw togehter a better harness than just printing, parallelized it with a 15 worker ThreadPoolExecutor and a chunk size of 10, and let it go! It took about 30 minutes to process all 4000 images, leaving us with 108 positive images. After manual review, 8 of those positive images were false (about 6%) and we got a nice 100 shots of Pantheon Season 2 that contain Raine!
For what we need, this worked out pretty well. A healthy and diverse set of reference images, many of which would have been hard to notice myself. All in all, it took about 12,300,000 tokens with gpt-4o-mini for the final long run, and including all my testing, I spent only $2.06 for all 4k images and many evaluation runs! I'd say I'm very impressed with 4o mini and will definitely be coming up with more things to try it on.
Oh, I'd show you a little gallery of Raine shots, but I think you should just go watch the show and see them for yourself. Have fun!
Onto Part 2 - Gaining A Dimension
This will, unfortunately, be left to another time! Raine looks frankly really weird and has a lot of internal void space between the legs and in the handle of the rice cooker. For the same reasons that YOLO and friends would be difficult to use on her, the existing pre-trained image-to-3d models don't really do great here either! I'll be back with some news on artists or maybe a quest to learn blender myself another time.
In the meantime, go watch Pantheon! You won't regret it.